Member-only story
Disaster Recovery in AWS: Strategies and Best Practices for Business Continuity
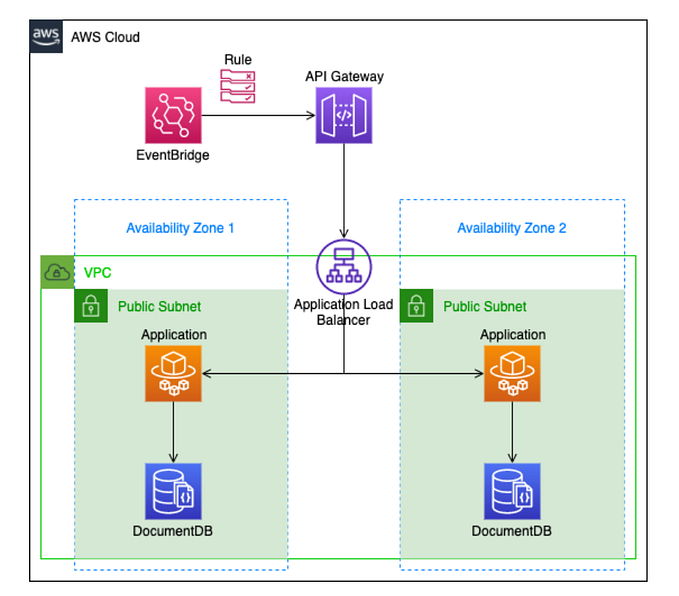
Disaster Recovery Overview
Disasters can be any unexpected events that negatively impact a company’s business continuity or finances, from natural catastrophes to hardware failures or even human errors. In the world of cloud computing, Disaster Recovery (DR) refers to the strategies and actions put in place to quickly recover and maintain essential functions after a disaster. In AWS, disaster recovery takes advantage of cloud flexibility and scalability to offer a range of solutions for business continuity, from traditional on-premises DR to cloud-based or multi-region strategies.
Understanding RPO and RTO
Two key terms in disaster recovery are RPO and RTO:
- RPO (Recovery Point Objective): This defines the maximum amount of data loss (in terms of time) an organization is willing to tolerate in the event of a disaster. For example, if an RPO is set to one hour, the system should recover with no more than one hour’s worth of lost data.
- RTO (Recovery Time Objective): This defines the maximum acceptable time to restore services after a disaster. For example, if the RTO is four hours, your disaster recovery plan should enable recovery and restoration of services within four hours of the incident.
AWS provides various strategies with different RPO and RTO levels, allowing organizations to select the best option based on cost…